I have the following collection:
{
_id: 12345,
quizzes: [
{
_id: 111111,
done: true
}
]
},
{
_id: 78910,
quizzes: [
{
_id: 22222,
done: false
}
]
}
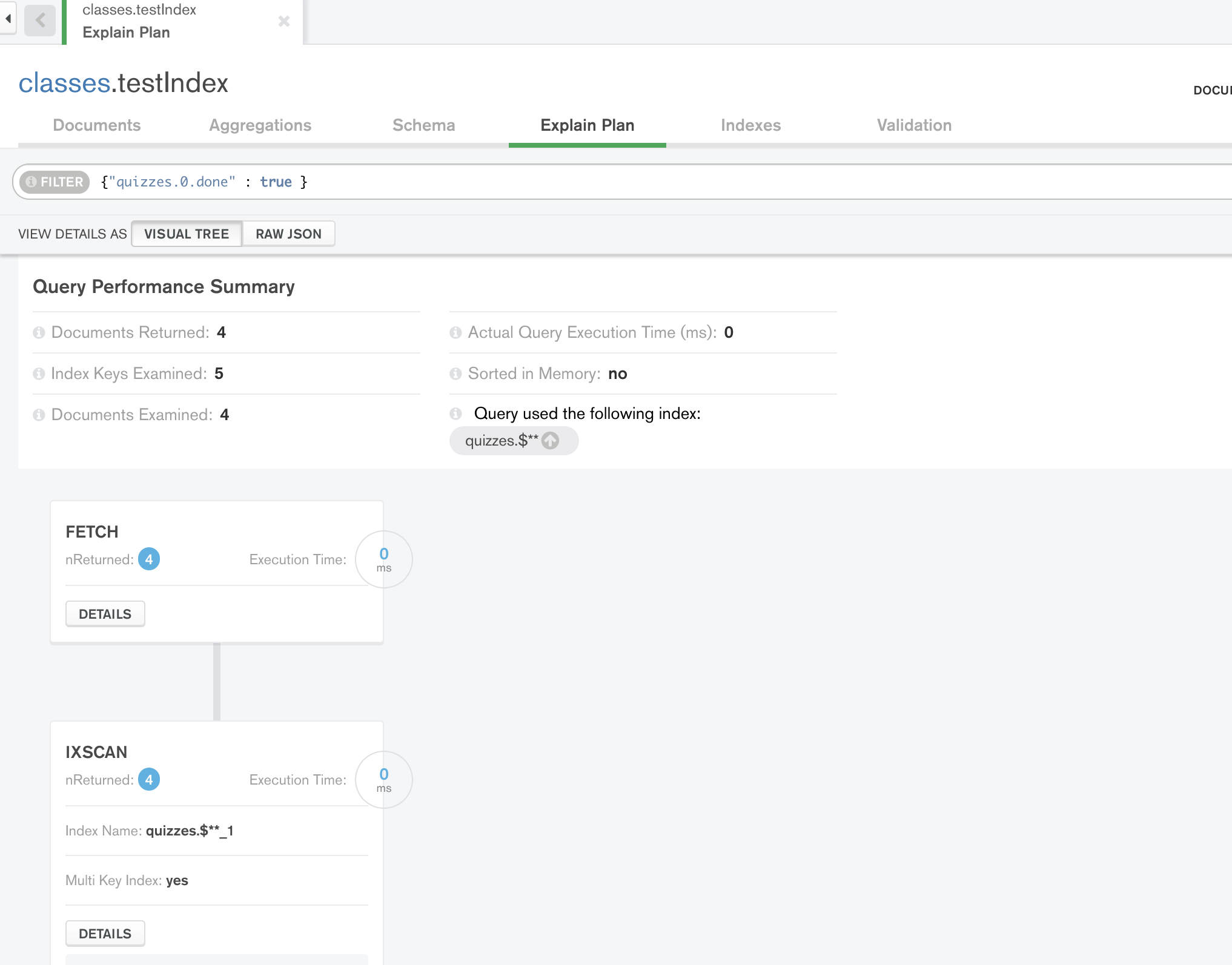
I want to select the documents where a certain quiz from the quizzes was done and want to make sure that it uses the appropriate index. So I use the following query:
Answer.find({ 'quizzes.0.done': true }).explain('queryPlanner');
Which returns:
queryPlanner: {
plannerVersion: 1,
namespace: 'iquiz.answers',
indexFilterSet: false,
parsedQuery: { 'quizzes.0.done': [Object] },
winningPlan: { stage: 'COLLSCAN', filter: [Object], direction: 'forward' },
rejectedPlans: []
}
The query is not using any index as seen from the output. I have tried the following indexes and none get used:
{ quizzes.done: 1 }
{ quizzes.[$**].done: 1 }
{ quizzes: 1 }
The only 1 that actually gets used:
{ quizzes.0.done: 1 }
However this is not really practical as I may target any quiz from the quizzes array not just the first one. Is there a certain syntax for the index in my case or this is a current limitation of mongodb?
Thanks in advance
Hi @Michael_Azer,
MongoDB support multikey indexes on array subdocs.
You can just index quizzes.done and it should support the query. Having said that true or false are not that selective so perhaps a full scan can in some cases be faster (collscans are optimised and return better than jumping between docs and index entries)
Best regards
Pavel
Hi @Pavel_Duchovny
I tried the query using Mongo compass and Mongoose (NodeJS) and the index quizzes.done is NOT used even though a multikey index should be created as you say.
Take a look at the following screenshots for confirmation:
https://i.ibb.co/JvXmxr9/Screen-Shot-2020-08-19-at-11-18-43-PM.png
https://i.ibb.co/WDxxcZC/Screen-Shot-2020-08-19-at-11-18-51-PM.png
If I modify the query to be like
Answer.find({ 'quizzes.done': true }).explain('queryPlanner');
The index gets used.
However the fastest index that works that I found is quizzes.0.done but this is not dynamic enough.
This means I would have to create quizzes.1.done quizzes.2.done …etc which does not make sense.
Thanks!
Hi @Michael_Azer,
So you are trying to query quizzes.<number>.done explicitly? If yes the engine will not be able to map this query shape to the index.
Have you tried using $arrayElementAt instead?
Additionally, test if specifying a hint with the multikey yield better results.
Best
Pavel
Hi @Pavel_Duchovny 
-
Yes I’m filtering a certain array element index like above.
-
I tried $arrayElementAt but it was extremely slow
-
Hinting the multikey index did not help
-
To summarize, the fastest index is quizzes.0.done
-
Can you please add a feature request for a new variation of a wildcard index like quizzes.$**.done so that we don’t have to create quizzes.0.done , quizzes.1.done , quizzes.2.done …etc?
That would be very helpful.
Thanks again Pavel for your effort.
Regards
Hi @Michael_Azer,
I will try to search for a better solution.
Have you tried a wild card index on this collection?
You can file a feature request here https://feedback.mongodb.com
Thanks
Pavel
Hi @Pavel_Duchovny
Yes. I tried quizzes.$** or do you mean something else?
This was very slow again.
Please update me if you find a better solution.
Thanks!
Hi @Michael_Azer,
In my repro both indexes the wild card and the multikey worked for me
I am not sure why you can’t utilize them.
Best regards,
Pavel
Hi @Pavel_Duchovny
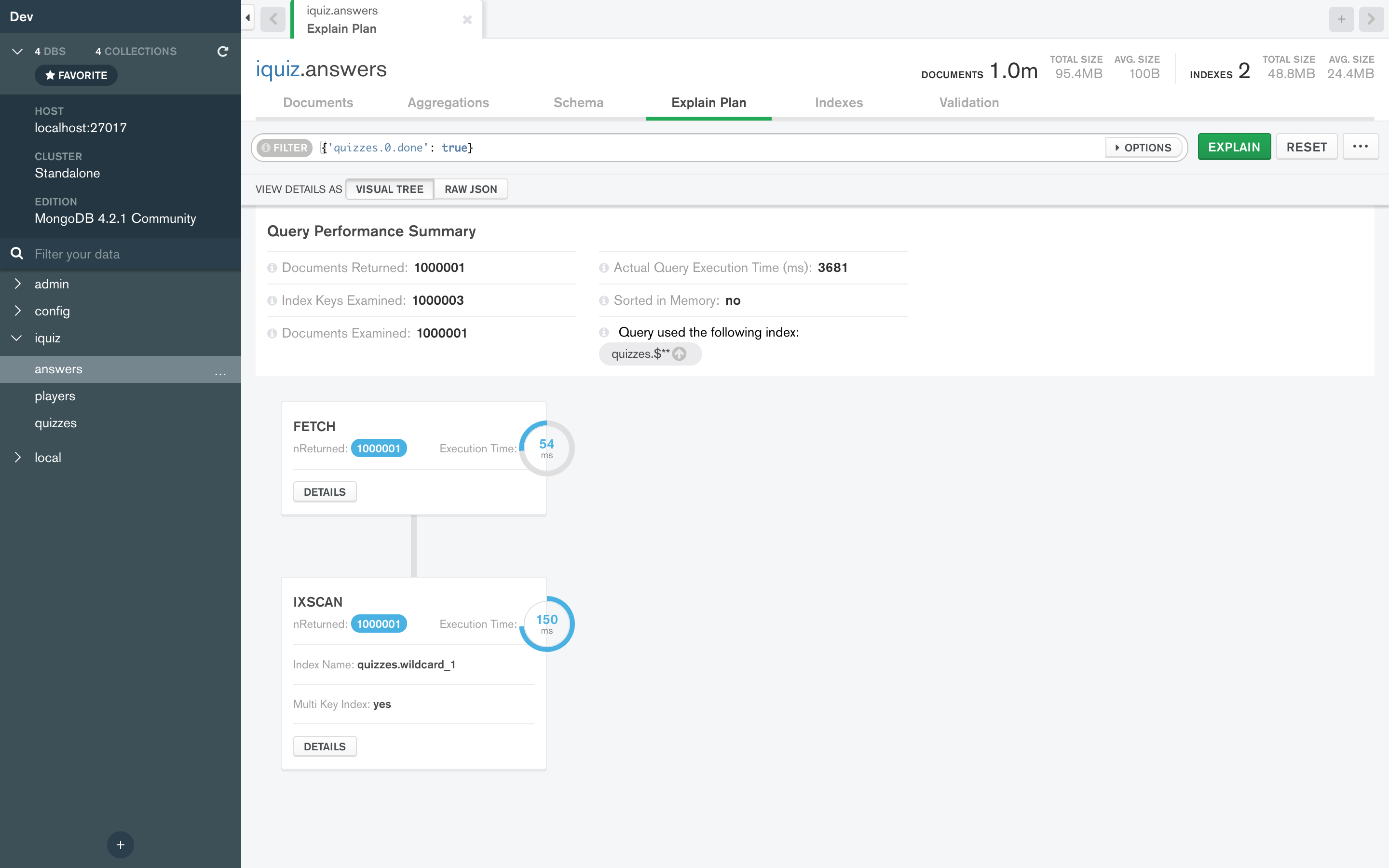
Yes, the wildcard index quizzes.$** gets used but it’s much slower like I explained before.
Judge how it performs on a large database:
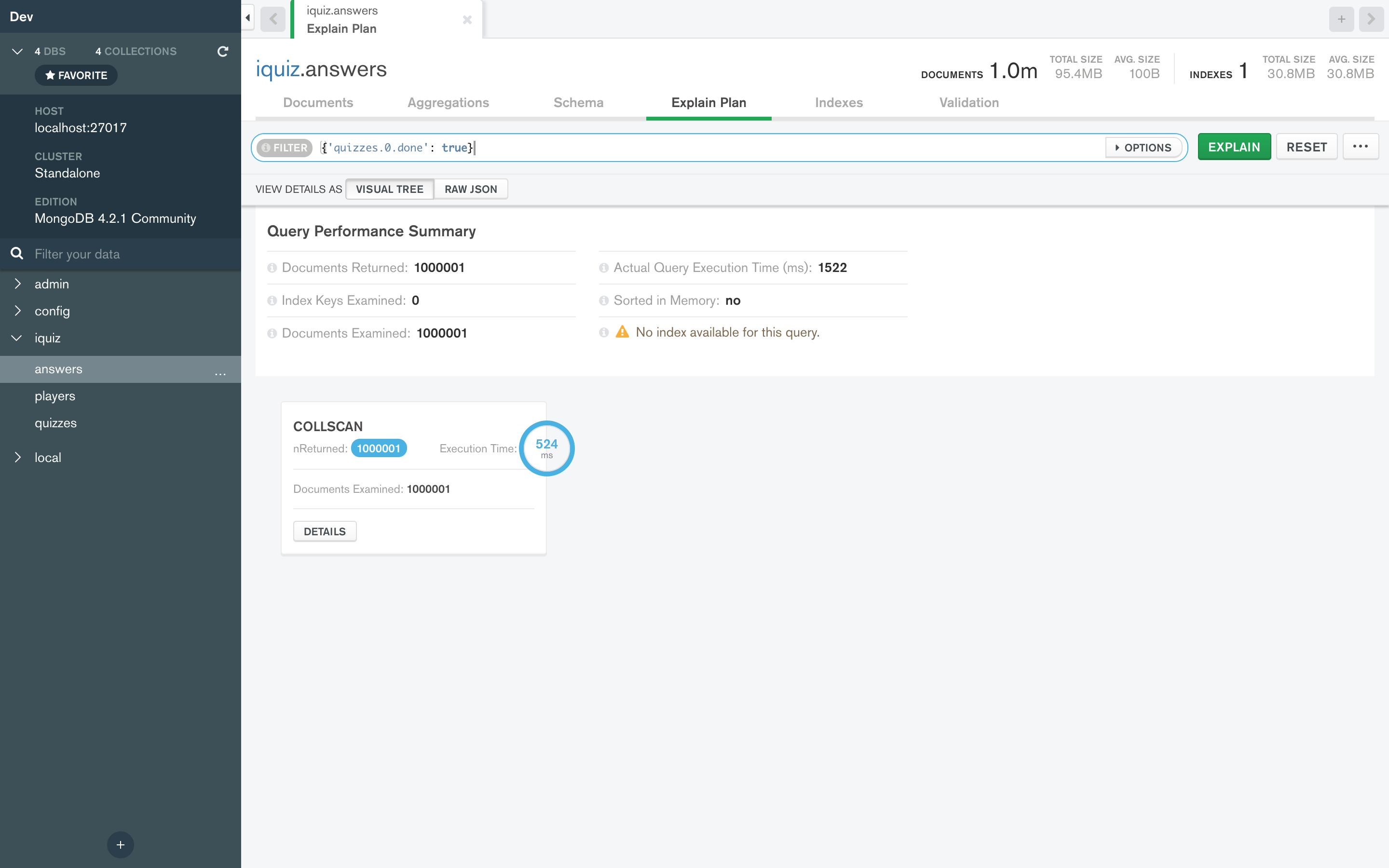
Even without any index at all it’s much faster:
If by multikey-index you mean just quizzes, I tried it and it won’t get used by the query without hinting.
With hinting, the multikey-index would be as slow as the wildcard index above.
Thanks in advance
Regards
Michael
Hi @Michael_Azer,
Looks like all documents needs to be scanned to get the values so an index scan will not make sense but a full scan might be optimal.
The scans are better then full index scan like the one you showed.
Why would you specifically query a position element? I mean maybe there is a better query for what you are trying to achieve.
Best
Pavel
Hi @Pavel_Duchovny
This is a game and I need to get the ranking of a player in any quiz (level) compared to all the other players who finished the level.
So I get the number of players who finished the quiz and another query to get the ranking.
All I’m doing is counting with many different queries to get different stats like this. I don’t actually retrieve the documents themselves.
Thanks
Hi @Michael_Azer,
Which fields you are ranking on, is it like score?
Perhaps you can test a partial index with partailFilterExpression quizzes.done : true and index the ranking fileds.
Thanks
Pavel
Hi @Pavel_Duchovny
Yes. There is a score field for each quiz solved and each player has a document with the quizzes array holding those scores.
I modified the schema so that there is a score field ONLY for the finished quizzes.
So I check if { $exists: true } on the score field to get the number of players who finished the quiz and I no longer need the done field to do that.
I calculate the ranking of a player on a certain quiz based on the score field on the quiz.
To get the correct ranking I found that I have to select only distinct scores so that multiple players having the same score would have the same ranking. Unfortunately, the distinct made the query even slower!
Now even the quizzes.0.score index that I mentioned before is making the query slightly slower than without it.
I tried the partial filter expressions and it doesn’t make sense for my case as any player that I’m getting the rank for could have a score of zero which means the filter would be { $gte: 0} which basically selects the whole collection. I tried it and it was slower than without index.
For now, I no longer use any index as this seems the fastest for my case.
Please update me if you have other suggestions.
Thanks in advance
Regards
Michael
Hi @Michael_Azer,
I need to compare explian(executionStats) from each type of query to understand the query pattern and why its slower or faster.
The COLLSCAN algorithm is pretty optimized and if for your calculations you need to scan a large portion of the collection its not surprising that COLLSCAN is better.
I always say that COLLSCANS are not a bad thing they just not advised if you can filter better using an Index.
Best regards,
Pavel