I’m starting with Mongo and even after reading the documentation I’m not sure if I’m in the right way.
I have more than 100 big JSONs (2 - 150Mb) with the resullt of Cucumber execution to save everyday.
If I save the JSON with GridFs I can’t query in keys inside the JSON, right? So, how can I save big files and keep some information of them to make queries?
Is MongoDB a right choice to save this kind of files?
I tried with mongoimport treating each json as a document inside a collection ‘executions’, it worked perfectely in files with less then 16Mb but I’m getting error when I try to import JSONs with more than 16Mb.3
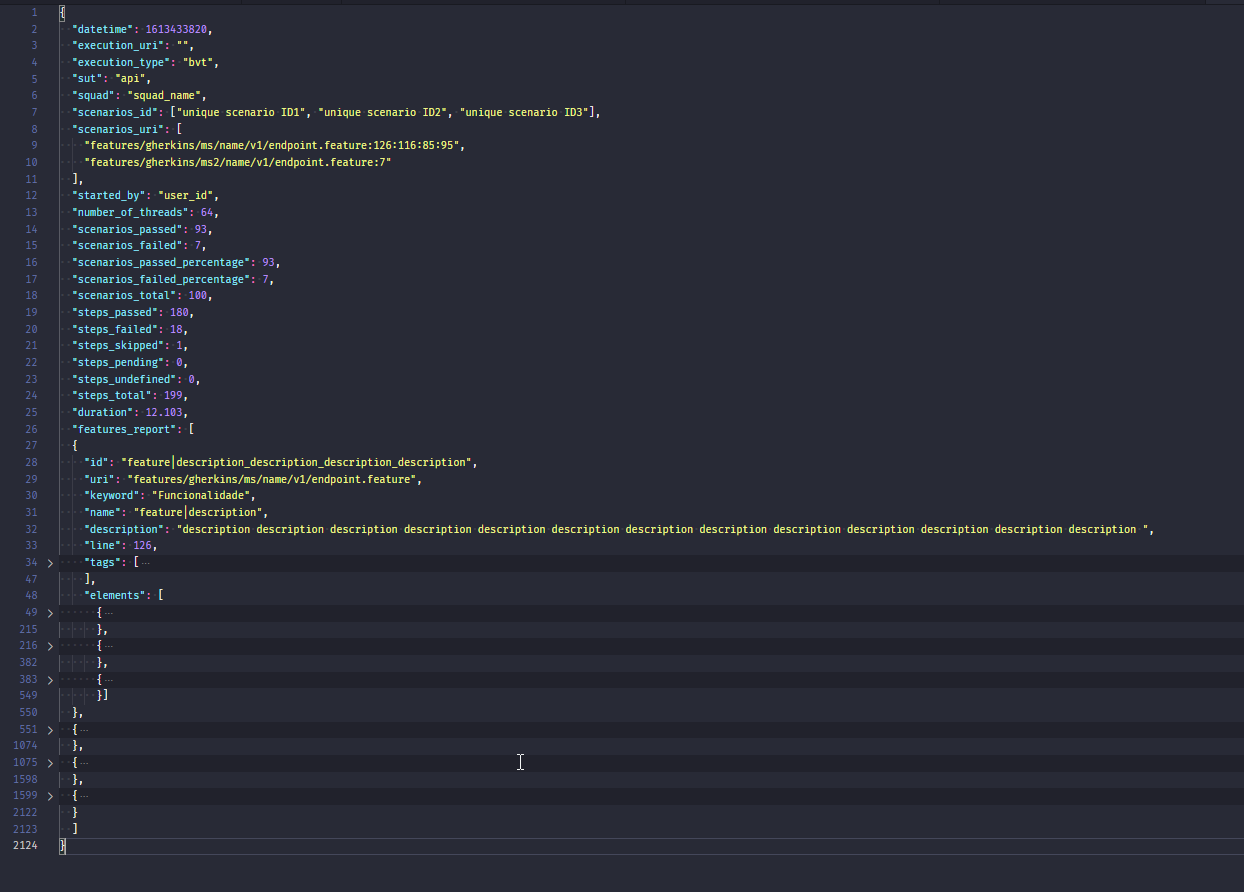
I do not know how the files are organized so it is hard to tell. However I suspect that 1 file is 1 document, and the size limit for one document is 16Mb. There is may be a way to split that one document into its sub-documents. For example, if the document looks like:
it is possible to remove the outer braces and brackets and insert only the log_entries.
Could you provide a link to the problematic file? Since it may contains sensible information, I can give you an upload link to my dropbox. May be you can redact the sensible information.
This is like I suspected. The whole file is a single document. The first fields, from datetime to duration, are some kind of an enveloped shared by features_report.
What I would do is use something like jq to put the envelop fields in one document and then extract each *features_report in separate documents. The insert the envelop document in a collection (say envelops) and then each features_report into another collection (say reports) while making sure each features_report contains a reference to its envelop document.
Alternatively, with jq again duplicate the envelop fields in each features_report.
But honestly, if I look the different features_report, they all look alike. Somewhat akin to an infinite loop or recurring failure.