Hi,
I’d like to insert binary files into MongoDB and I’d like to avoid GridFS, all files will be smaller than 10 MB.
But I noticed quite high memory usage (on the client side) while inserting binary file into MongoDB.
My setup:
Python 3.9.4
pymongo client 3.11.4 (with C extensions)
Local MongoDB in Docker: version 4.0
Linux Ubuntu 21.04, kernel 5.11.0-17-generic
I created test binary file with exactly 10 000 000 bytes. This snippet works (file is correctly stored). But when trying to insert it using this snippet
import pymongo
client = pymongo.MongoClient('localhost', 27017)
db = client['test']
collection = db['test']
with open('file', 'rb') as f:
file_content = f.read()
collection.insert_one({'file': file_content})
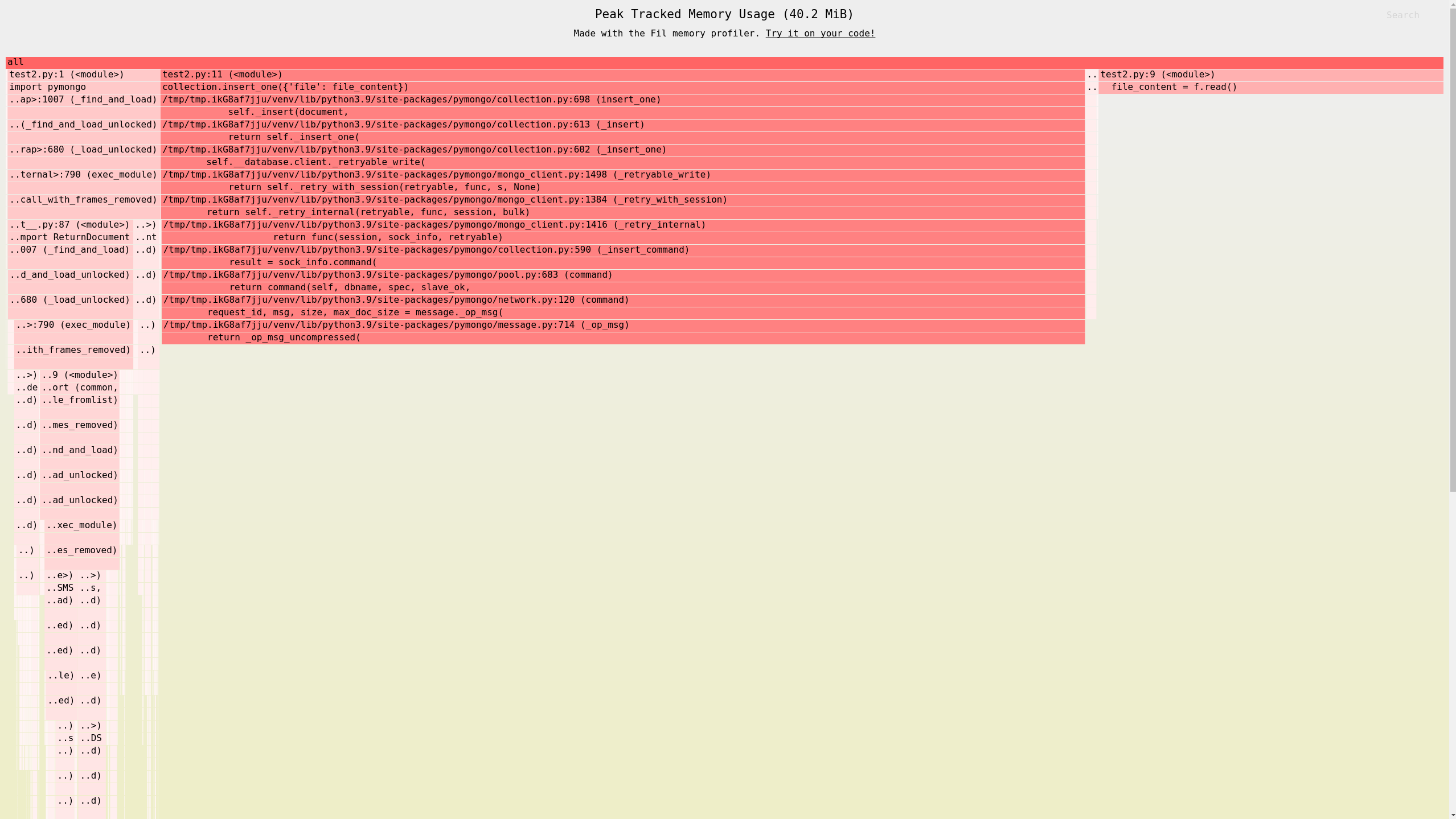
and using memory profiler (filprofiler), pymongo driver use 2.5 times more memory just for inserting this file (see attached image). Stacktrace ends with pymongo function _op_msg_uncompressed.
When you have worries like that, the real first thing to do is to establish a baseline for your benchmark.
In this case, I would check different scenarios.
Check memory usage with a 1 byte file. That will establish a baseline for the simply using the API.
Check memory usage for reading the file into file_content. This will establish a baseline or simply reading the 10MB file. Make sure you use file_content somehow to make sure the optimizer does not simply ignore the statement if you do nothing with the variable. (I do not know python enough to know if it could or not)
Check memory usage without calling insert_one() but while creating the object { "file" : file_content }. If python creates the object by coping file_content vs referencing it then you might end up with twice the use memory right there. Note that the optimizer might not use the memory if you do nothing with that object. I suggest to assign it to a variable that you export, this way we hope the optimizer won’t optimize. This will establish a baseline for simply create the JSON document.
The other memory usage would then be the network buffer used to send the API call and its payload over the wire. But that’s harder to find and have no clue how I could do it with python.
Memory consumption of this snippet with 1 byte file is ~5 MB, from memory profiler it looks most of the memory is used up by importing libraries (pymongo). So this is our baseline.
file_content = f.read() uses additional 10 MB as expected (total of 15 MB = 10 MB + 5 MB). If I just read the content of the file and write it back into another file, it still use total of 15 MB (to test that file_content is actualy used).
When I’m creating dictionary { "file" : file_content } Python pass it as reference. No additional memory is used. So, up to the point before calling insert_one, total memory usage is 15 MB (10 MB for file + 5 MB baseline).
When doing insert_one it uses additional 25 MB (that’s the 2.5 multiplication I was talking earlier, just the insert_one, I’m ignoring already loaded file into memory), so the total memory consumption is now ~40 MB (5 MB baseline + 10 MB loaded file + 25 MB from insert_one).
So that leads to my original question (now asked much more clearly - thanks for the assistance): Why inserting a 10 MB file use another 25 MB of memory, if the file is already loaded in the memory ?
I don’t know python enough to help further but with what you share I really hope someone will step up and we all will learn. I will follow this thread closely.
Hi @Petr_Klejch, thanks for reporting this issue. I suspect pymongo is working as designed here and this is a side effect of the way that we serialize messages in our C extensions. However, we can probably optimize this path to reduce the peak memory usage. I’ve filed an optimization ticket here: https://jira.mongodb.org/browse/PYTHON-2716
Please follow the Jira ticket for updates. For convenience, I’ve copied the description here:
Our theory is the extra memory comes from using the buffer.h API in our C extensions. The issue is that when a buffer needs to grow we simply double the size until the buffer is large enough to accommodate the new write. So in this case:
Client inserts a document containing a 10MB binary string
pymongo enters the C extensions (_cbson_op_msg) and starts encoding the document to a buffer
pymongo calls buffer_write() with the 10MB byte-string
the buffer doubles in size until it reaches ~10-16MB
pymongo finishes encoding the message to the buffer
pymongo calls Py_BuildValue to convert the buffer to a Python bytes which creates a copy taking at least an extra 10MB.
we deallocate the buffer to free ~10-16MB.
So in total the peak memory is around 25MB. We should investigate if it’s possible to reduce the memory usage by using a zero-copy method to convert from the internal buffer to a Python bytes object.